CAS Software AG ist Marktführer für Kundenbeziehungsmanagement (CRM) im deutschen Mittelstand. Ob Marketing, Vertrieb oder Service – Anwender profitieren von effizienten Prozessen auf einer einheitlichen Datenbasis.
CAS Software AG ist Marktführer für Kundenbeziehungsmanagement (CRM) im deutschen Mittelstand. Ob Marketing, Vertrieb oder Service – Anwender profitieren von effizienten Prozessen auf einer einheitlichen Datenbasis.

Heute im Fokus das Thema Adress- und Datenqualität von Address Solutions
Wie gut ist mein Datenbestand? Wie kann ich die Datenqualität messen? Welche Probleme finde ich in den Daten? Welche Auswirkungen hat das auf die Prozesse? Welcher Handlungsbedarf ergibt sich daraus? Was muss ich machen? In welcher Reihenfolge findet die Abarbeitung statt? Wie kann man einen dauerhaften Prozess etablieren? Wobei hilft mir Address Solutions in meinem Unternehmen?
Das sind die typischen Fragen, die jedem zu diesem Thema in den Kopf kommen. Die Antworten darauf liefert dieser Erfahrungsbericht.
Untenstehend finden Sie unsere wichtigsten Erkenntnisse aus einem spannenden Gespräch mit Jörg Kleinbrahm und Ralf Geerken. Beide sind Geschäftsführer bei Address Solutions.
- AS Inspect dient zur Problemerkennung und -behandlung
- Aufbau der Prüfschritte
- Dublettenprüfung
- Die Rolle von KI
- Unser Fazit
AS Inspect dient zur Problemerkennung und -behandlung
Ziel der Applikation ist:
Mit wenig Aufwand soll der Anwender in die Lage versetzt werden, sich einen Überblick über die Datenqualität zu verschaffen. Das System erkennt durch das Address Solutions Regelwerk, welcher Inhalt in den Feldern enthalten ist und benennt die eindeutig erkannten Felder entsprechend. Nicht erkannte Felder werden einfach durchnummeriert. Der Anwender benennt diese Felder mit dem entsprechenden Label. Falls AS Inspect die Felder nicht korrekt erkennt, kann man anschließend diese manuell auf einfache Weise mappen. Die Zuordnung von Kriterienbezeichnungen können angepasst werden. Falsch erkannte Felder können einfach umbenannt werden.
Die Vorteile einer guten Felderkennung und einer individuell möglichen Benennung zeigt sich bei einem beispielhaften Blick auf den Aufbau einer Kontaktadresse:

Für die folgende Vorstellung des Produkts ist ein Testdatenbestand von ca. 25.000 Datensätzen als CSV-File vorbereitet worden. Man wird in wenigen Schritten durch den Prüfprozess geleitet.
Die Verarbeitungszeit bei Address Solutions ist sehr schnell
25.000 Datensätze sind nach 2 bis 3 Minuten analysiert, bei 100.000 Datensätzen wären das ca. 10 Minuten Laufzeit, um erste Ergebnisse zu sehen. Also alles in einem hohen Tempo.
Fragen an das Team von Address Solutions:
- Kann man für den Import schon vorab ein Variablen-Set anlegen, welches dann immer wieder verwendet werden kann?
- Erkennt man beim Import schon Anomalien? Beispielsweise eine falsche Reihenfolge des Geburtstagsdatums?
Die Antworten der Experten von Address Solutions sind:
- Natürlich kann man beliebig viele Variablen-Sets anlegen und unter einem aussagekräftigen Dateinamen in einem beliebigen Verzeichnis abspeichern!
- Beim Import werden die Daten absolut 1:1 übernommen, um dann anschließend Anomalien in den Daten zu finden. Wir möchten keine Daten schon beim Import ausschließen und für die spätere Analyse verlieren!
Was sind die Prüfschritte im Einzelnen?
Für den ersten Einblick finden 3 Prüfungen statt: Adress-, Namens- und Dublettenprüfung.
Der Prüflauf erzeugt – wie schon erwähnt in kürzester Zeit – nach ca. 2 Minuten (bei ca. 25.000 Datensätzen) drei Standard-Reports: Diese beantworten deutlich folgende Problemfrage:
- Gibt es Probleme im Datenbestand? Wenn ja, welche sind das?
Neben den drei Reports erhält man noch eine Füllgrad-Analyse: Welche Felder sind überhaupt gefüllt? Unabhängig der Qualität des Inhalts. Mit einer Ampel bekommt der Anwender einen direkten Hinweis zur Schnelleinschätzung, wie gut oder weniger gut der Zustand der Daten ist.
Nun geht es in die Details
Für jeden Prüfvorgang mit „AS Inspect“ zeigt einem das System, neben einer weiteren Ampel mit Erklärungen, die Problem- und Schwachstellen. Der User bekommt kategorisiert Hinweise innerhalb von 9 Fehlerkategorien:
- Vollständig korrekt, 2. Normstrukturierungen, 3. Struktur korrigiert, 4. unbekannte/falsche Anrede korrigiert, 5. unbekannter Titel, 6. unbekannter Vorname (siehe ausländische Vornamen), 7. unbekannter Nachname, 8. mehrere Felder mit ungültigem Inhalt, 9. Personengemeinschaft.
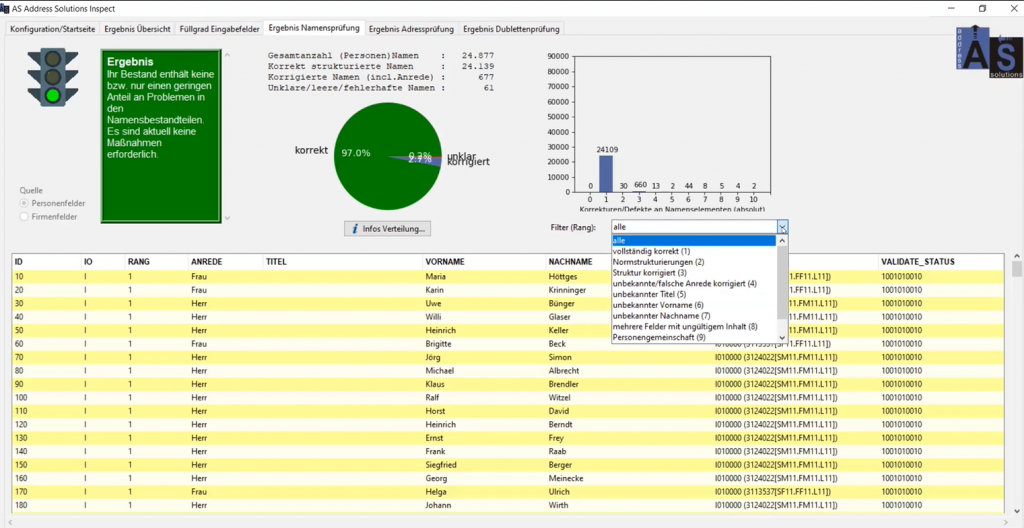
Das System schlägt dann gleich die möglichen Korrekturen vor wie vertauschter Vor- und Nachname, Vor- und Nachname in einem Feld, fehlerhafte Groß- und Kleinschreibung und einige mehr.
Weitere Optimierungsmöglichkeiten sind zum Beispiel die Anrede (auf Basis der Vornamen wird die korrekte Anrede definiert). Spezialfälle wie Andrea, wenn es sich wie im Italienischen um den männlichen oder weiblichen, aber im Deutschen um den weiblichen Vornamen handelt, werden nicht korrigiert, sondern erkannt und für eine manuelle Korrektur ausgewiesen. Unbekannte Vornamen bzw. Nachnamen (die z. B. Ziffern enthalten) werden hervorgehoben.
In den meisten Fällen sinnvoll ist auch das Aufteilen von Personengemeinschaften: z. B. Herbert und Astrid stehen in einem Vornamensfeld. Daraus werden dann – wenn das gewünscht ist – zwei Datensätze angelegt. Selbst bis zu 3-4 Namen können so separiert werden.
Hinter jeder Analyse gibt es den Bericht auf dem Screen oder als ausführliches PDF.
Analyse der korrekten Anschrift
Für jeden Datensatz gibt es einen eigenen Score-Wert. Beispielsweise einen Score für die PLZ, einen für den Straßennamen und einen für den Ortsnamen. Das Ergebnis ist der Gesamtscore für alle drei Werte sowie zusätzlich einen Statuscode, der ergänzende Hinweise zu Anomalien gibt.
Weitere Hinweise sind z. B. PLZ, Straße bzw. Ort konnten automatisch korrigiert werden, Hinweise zu PLZ und Straße oder PLZ, Straße und Hausnummer passen nicht zusammen. Oder es befindet sich eine unerwartete, ausländische Adresse in den Daten. Der Ortsteilname, der im Feld Ort steht, wurde durch den korrekten Ortsnamen ersetzt.
Jeder Datensatz bekommt einen Wert für eine Rangreihenfolge. Wenn ein bestimmter Wert erreicht wird, kann der Kunde diesen korrigierten Datensatz sofort wieder ins System einspielen. Je höher der Wert/Rang, desto mehr muss eine manuelle Bearbeitung erfolgen.
Ergebnis
Nach Abschluss dieser Arbeit hat man eine hervorragende Ausgangsbasis für den Dublettenabgleich.
Das Ziel ist dabei, so wenig wie möglich dem Adressqualitäts-Team an manueller Arbeit zu überlassen.
Kommen wir nun zur Dublettenprüfung
Wenn man an dieser Stelle einen hohen Wert an Dubletten im Unternehmen hat, kann die Bereinigung dieser schnell zu einer kleinen Herkulesaufgabe werden. Aber diese Arbeit lohnt sich dennoch und in jedem Fall.
Welcher Zweck steckt hinter der Zusammenführung? Hier gilt es scharfe oder weiche Kriterien zur Bewertung anzuwenden. Daher ist auf Over- und Underkill zu achten.
Zusätzliche Variablen, wie E-Mail-Adresse, Alter bzw. Geburtstag oder Kaufdaten helfen zu entscheiden, wer eine Dublette ist und wer nicht. Wer ist eine Kopf- und wer ist eine Folgedublette?
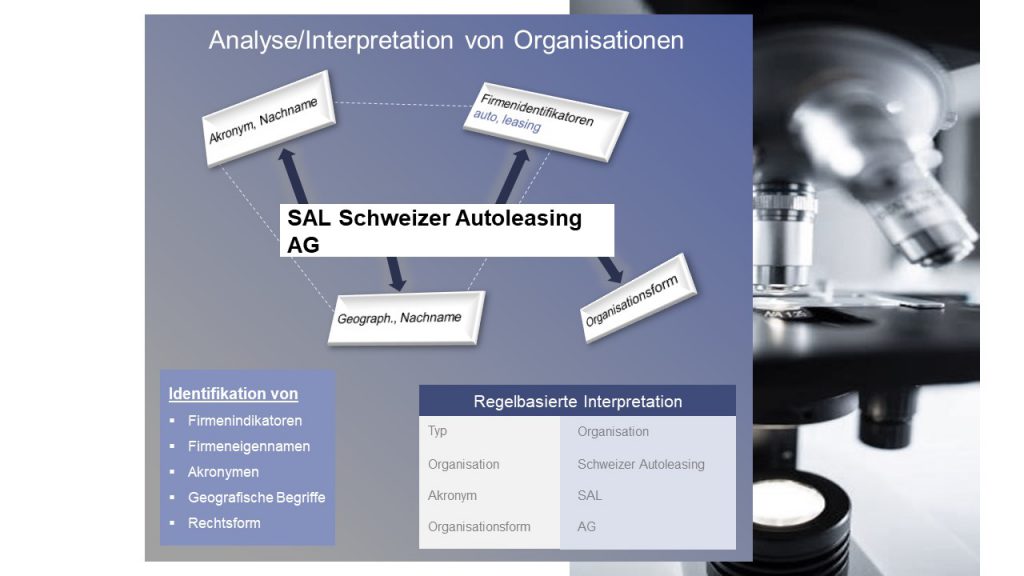
Auflösen von Namensbestandteilen
Die Kombination aus a) wissensbasierter und b) regelbasierter Interpretation hilft, selbst komplexe Wortverkettungen sauber aufzulösen. Beispiel Prof. Dr. Frank-Walter Baron von der Mühle, Arzt.

Mit Hilfe der europäischen Wissensdatenbank nutzt Address Solutions ihre Erfahrungen, um die Namensangaben möglichst automatisch zu bearbeiten und aufzulösen. Auch das Beispiel für SAL Auto-Leasing zeigt die Funktionsweise für Organisationen gut auf.
Ein Highlight ist die Vielfalt der Vergleichsverfahren bei Address Solutions
Damit kann ein Unternehmen innerhalb eines Felds oder zwischen Feldern vergleichen, um Dubletten oder Ähnliche zu finden. Z. B. Ursula und Uschi, oder im Englischen die Vornamen Richard oder Dick. Alle möglichen Schreibvarianten werden in sehr feinen Filtern „herausgewaschen“.

Es gibt keinen Standard. Aber es gibt eine Menge sehr nützlicher Vorlagen, welche auf die beliebige Datenlage angewendet werden können. So zum Beispiel scharfe oder weiche Abgleiche bei reinen Privatpersonenbeständen, reinen Firmenbeständen oder gemischten Datentöpfen. Diese Konfigurationsvorlagen können auf einfachste Art und Weise geladen und, falls wirklich erforderlich, weiter optimiert bzw. verfeinert werden.
Die verschiedenen, zur Verfügung stehenden, mathematischen Methoden haben alle Vor- und Nachteile. Deshalb werden sie vom Address Solutions Team ganz speziell auf die jeweilige Problemstellung des Kunden hin ausgewählt und mit maximalem Nutzen eingesetzt.
Ein Hinweis zur Qualitätssicherung ist uns wichtig
Es gibt Vergleichsmethoden, die auf Basis statistischer Verfahren ganz individuell auf den Inhalt der zu vergleichenden Felder abgestimmt sind, z. B. maßgeschneiderte Vergleichsverfahren für Vornamen, Nachnamen, PLZ, Ort, Straße, Haus-Nr., Geburtsdatum, Telefonnummer, Mailadressen, etc.
Ein Kunde muss sich also nicht aus mehreren hundert verschiedenen Methoden die jeweils besten Methoden heraussuchen. Hierbei unterstützt das Team von Address Solutions den Kunden durch diese kontextorientierten Vergleichsverfahren. Diese werden aus mehreren, geeigneten mathematischen Algorithmen gebildet.

Das Ziel: Möglichst granulare Teilergebnisse, die dann eingesetzt werden, um kundenindividuelle Regeln anzuwenden. Die Address Solutions unterstützt mit Verfahren, mit denen der Kunde beginnt. Danach werden verfeinerte Konfigurationen bzw. Methoden durch Address Solutions angewandt. Und der Kunde wird bei der Anwendung eng durch das Address Solutions Consulting-Team begleitet.
Aus den verschiedenen Teil Scores ist jedes erdenkliche Regelwerk zur Erkennung von Dubletten abzuleiten.
In Summe sind verschiedene Regeln, die in einer Entscheidungsmatrix zusammengeführt werden, die Grundlage für die entsprechende Online-Suche oder den Dublettenabgleich.
Die Ermittlung der Vergleichswerte und Entscheidungsregeln ist primär nur dafür da, dass Datensätze zu Dublettengruppen zusammengeführt werden. Das heißt, es werden Gruppenvorschläge für spätere Zusammenführungen erzeugt.
Zusätzliche Features
Durch das Regelwerk können Suchen nach speziellen Personengruppen durchgeführt werden, z. B. kann nach Betrügern oder verheirateten Frauen gesucht werden. Oder unterschiedliche Rechtsformen können zur Darstellung einer Holding eingesetzt werden.
Der Anwender/Kunde bekommt Hilfen, welche Regel in welchem Fall gegriffen hat. So kann der Kunde detailliert nachvollziehen, was passiert ist.

Ca. 20 bis 30 Regeln zusammengefasst ergeben ein Set aus Business-Regeln (die so genannte Entscheidungsmatrix), die beim Kunden zur Dublettenerkennung eingesetzt werden kann.
Als Zusammenfassung sieht man alle Regeln, die auf diese Dublette wirken, werden dargestellt. Hervorragende Transparenz!
Die Frage nach KI zaubert dem Address Solutions – Team ein Lächeln ins Gesicht
„Schon seit Jahren haben wir Analyse-Methoden im Einsatz, welche heute unter KI als Modetrend durch das Dorf getrieben werden. Der Einsatz und die Kombination außergewöhnlicher Methoden und Verfahren hat uns immer schon angetrieben. Seit der Gründung des Unternehmens beschäftigen wir uns damit“, lächelt Ralf Geerken in die Videokamera.
„Wir sind ursprünglich mit dem Consulting-Angebot gestartet. Nur fanden wir keine passende Software, die unseren Ansprüchen genügt hat. Somit haben wir diese nun selbst entwickelt. Wobei bei uns vor jedem Vergleich zweier Daten zuerst einmal genau analysiert wird, was im jeweiligen Feld steht. Damit versuchen wir, die menschliche Vorgehensweise beispielsweise beim Vergleich zweier Namen exakt zu simulieren. Nur in vielfach höherer Geschwindigkeit, als es der Mensch kann, und hoffentlich auch mit deutlich weniger Fehlern.“, ergänzt Jörg Kleinbrahm seinen Kollegen.
An einfachen oder komplexen Beispielen beweist das Team von Address Solutions Ihre Erfahrung:
Ein weiterer Beweis für die ausgeprägte Detailverliebtheit ist die Geschichte: „Wir haben einen unglaublich großen Erfahrungsschatz an möglichen Fehlerquellen. Z. B. Bei der Eingabe einer PLZ werden oft die ersten 3 Ziffern korrekt geschrieben. Die Ziffern 4 und 5 werde oft fehlerhaft eingegeben.“
Ein zweites Beispiel: Beim Vergleich von Hausnummer wird auch die mögliche Straßenseite berücksichtigt: Hausnummer „1“ und Hausnummer „2“ bekommen einen etwas niedrigeren Score als „3“ mit „1“. Oder Bereiche mit hoher Ähnlichkeitswert wie „Hausnummer liegt zwischen „6-10“ verglichen mit dem Wert „8“ werden berücksichtigt.
Das Ergebnis:
Maximal flexible Möglichkeiten. Die verschiedenen Tools von Address Solutions machen dann am meisten Spaß, wenn es um Millionen von Datensätzen geht.
Mit AS Inspect bekommt man auf Basis einer kleinen, aussagefähigen Datenmenge eine belastbare Qualitätsaussage. Man muss nicht mehrere Millionen analysieren. Es reichen ca. 25.000 Daten aus, einen bestimmten PLZ-Bereich zu überprüfen. Wird dann mit der Dublettensoftware anschließend die Dublettenbereinigung durchgeführt, stimmt die Qualitätsaussage natürlich immer noch!
In welchem Programm bearbeitet der Anwender die aussortierten Dubletten?
Es gibt bei Address Solutions einen Pool an Lösungen zur Bearbeitung, die schnell auf die speziellen Wünsche des Kunden angepasst werden können.
Auch die Bildung des Golden Records ist jeweils speziell zu entwickeln. Dieser wird aus dem kundenindividuell Basiswerkzeugen entwickelt, was ebenfalls durch vielfältige Vorlagen aus dem o. g. Consulting-Pool unterstützt wird.
Unsere Meinung hierzu:
Klasse, denn mit Standard-Tools wird oft mehr kaputt gemacht als Gutes erreicht. So aufwendig das vielleicht erscheinen mag, so hoch ist am Ende die Qualität. Mit der Weiterverarbeitung auf Basis der so genannten Vorlagen kann sich die Software komplett an die Vorgaben und Vorstellungen der Fachabteilung ausrichten. Diese muss keine qualitätsmäßigen Abstriche durch die Software hinnehmen.
Für welche Zielgruppen ist das Produkt geeignet?
Anwender in Firmen, die für Adressqualität, MarTech- und CRM-Themen zuständig sind.
Zielgruppe Unternehmen:
In der Regel ab 250.000 Datensätze.
Aber es gibt auch Beispiele von Kunden mit ca. 50.000 Kundendaten, denen die Pflege ihres wertvollen Datenbestands wichtig ist. Deshalb kommen die Tools von Address Solutions hierbei zum Einsatz.
Es gibt ca. 20 große Kunden, die die Address Solutions Lösungen innerhalb eines SAP-Systems durch den SAP zertifizierten Partner einsetzen. Diese Anwendungen haben zwischen 10.000 und 100.000 Datensätze zu verwalten.
Unser Fazit
Je weniger die Mitarbeiter manuelle Entscheidungen treffen müssen, desto besser. Es ist also schon erheblich, ob man 1% mehr oder weniger zur manuellen Bearbeitung aussortiert. Daher ist es absolut richtig, das Gewicht auf Qualität der Methoden zu legen.
Seit vielen Jahren werden bei Address Solutions KI-Verfahren eingesetzt und verfeinert. Aus zig verschiedenen Systemen werden Millionen Daten abgeglichen.
Jeder Kunde möchte die Möglichkeit der Dublettenbearbeitung individuell auf seinen Bildschirm durch maßgeschneiderte Lösungen – und bekommt dies auch perfekt geliefert.
Für jede Variable und jedes mögliche Vorkommnis gibt es ein Regelwerk als Basis, welches in sich noch einmal auf die jeweiligen Bedürfnisse und Besonderheiten der Firma justiert werden kann.
Address Solutions will nicht nur eine Software zur Verfügung stellen, sondern Address Solutions berät individuell anhand der Analysen. Dieses Thema ist immer kundenindividuell zu handhaben. Ein sehr guter Ansatz von dem Team der AS Address Solutions GmbH!
Welche Referenzen gibt es?
Für einen Überblick zu den Referenzen von Address Solutions wenden Sie sich gerne an:
Jörg Kleinbrahm
AS Address Solutions GmbH
Kaiserplatz 6
52222 Stolberg/Rheinland
Tel. : 0 24 02 / 76 49 19
Fax : 0 24 02 / 76 49 16
Mobil: 01 73 / 73 250 93
E-Mail: J.Kleinbrahm@Address-Solutions.de